
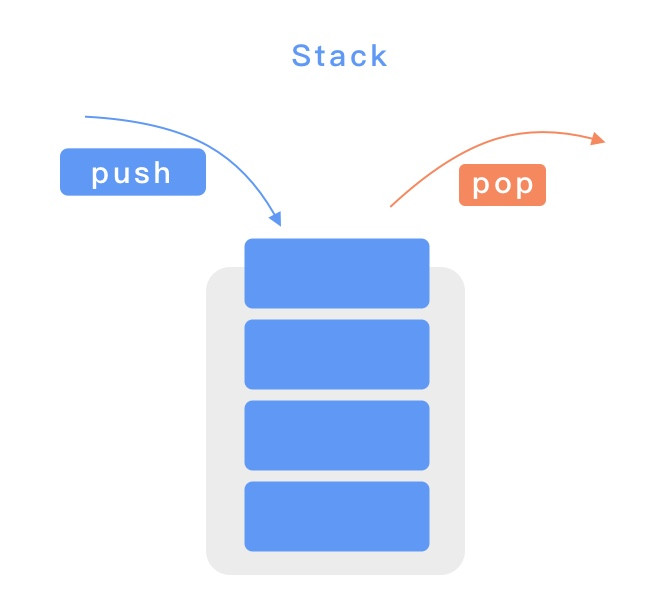
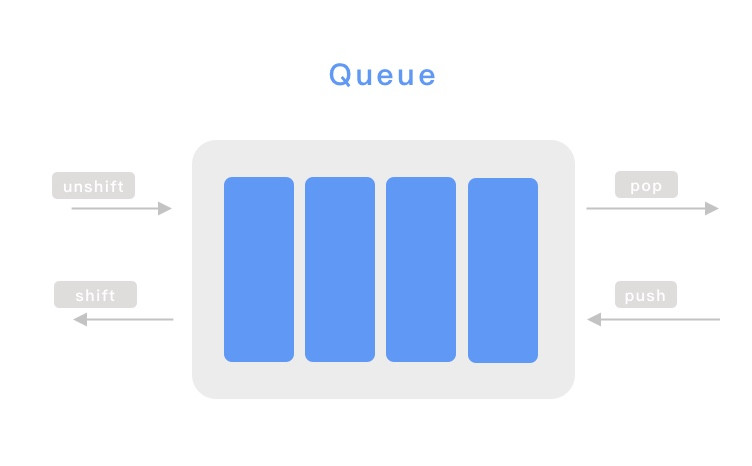
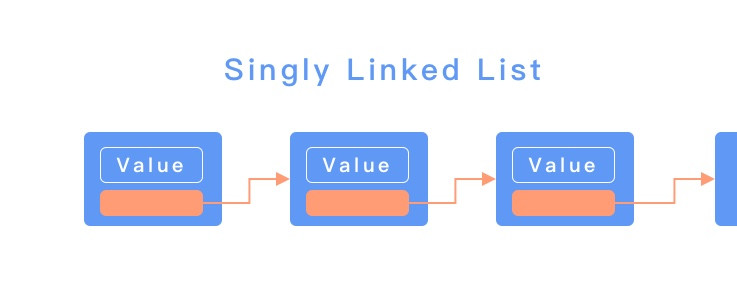
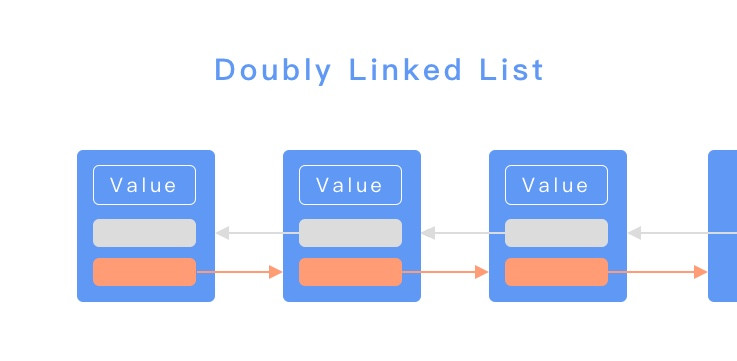


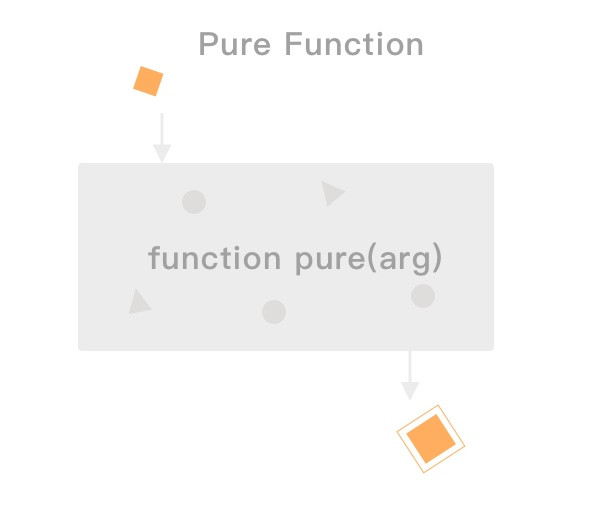
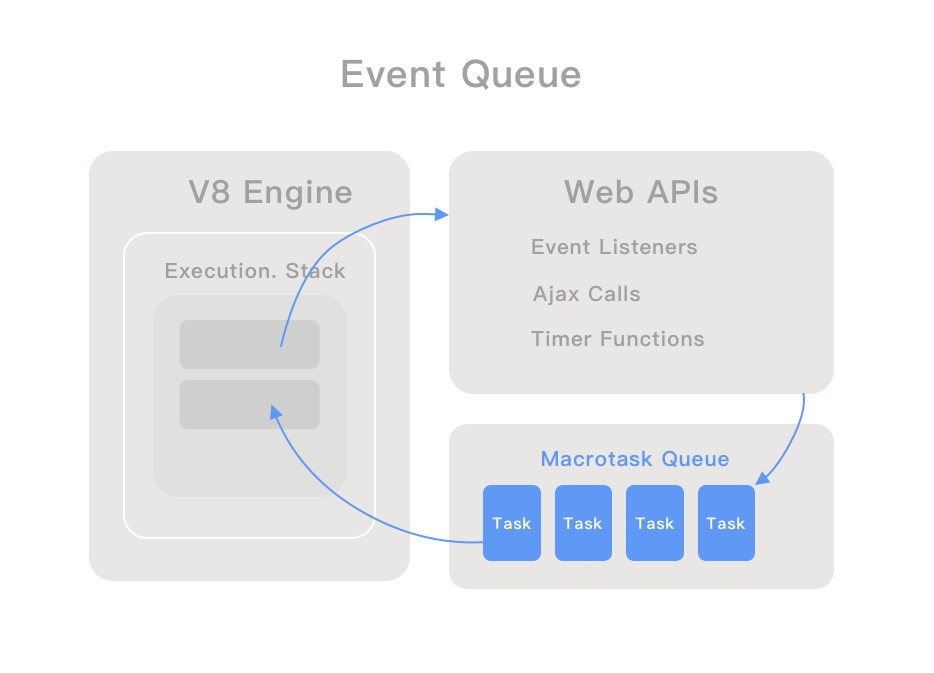
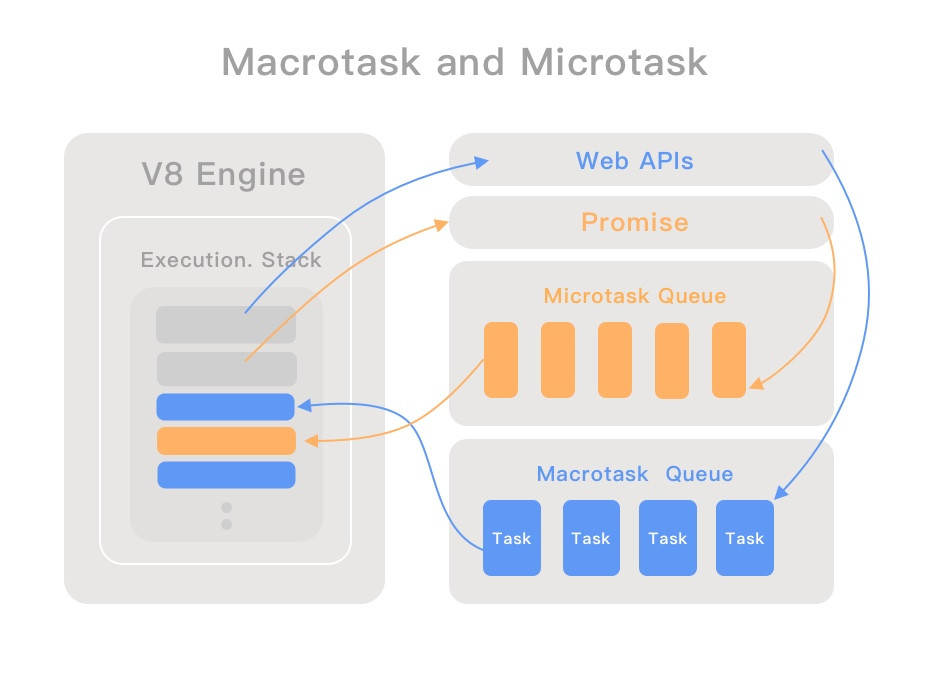

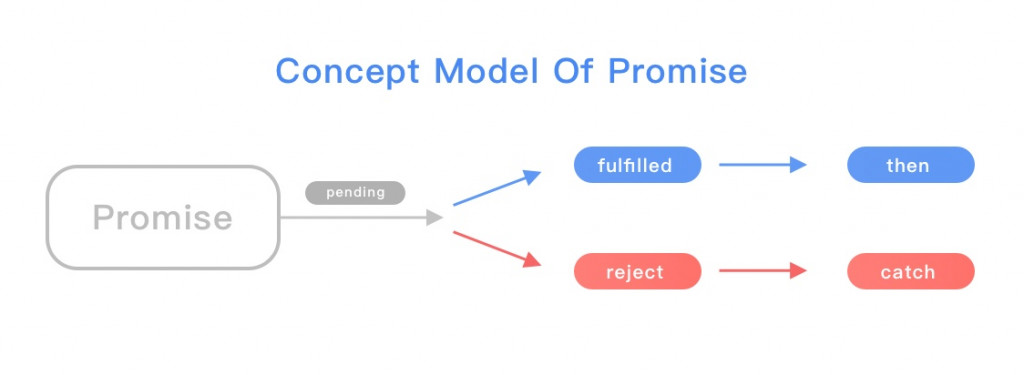


總算來到最後一天了,最後一天不會有技術內容,只會有很純的純 Mur Mur,想聽的再請留下。最後我打算記錄一下這三十天的感受,給其他沒參加過鐵人但是正在猶豫要不要參加的朋友參考。
普遍看到參賽方式有幾種情況:
- 精明準備型:囤好囤滿 30 天,完全事先囤貨所以內容超精緻
- 微囤貨:不事先準備太多,只囤幾天貨用來緩衝
- 硬派:「 什麼!?不就是要現學現賣才叫做鐵人嗎? 」的類型
老實說我認為如果不事先準備的話,那麼能不能完賽跟主題的選擇還有自身對主題熟悉度會有很大的關係,所以如果你也正在思考要不要參加,可以從這點著手。如果主題是你想寫但不熟,可以考慮現在開始到下次開賽前先慢慢累積文章量;或者你覺得對主題比較上手,可以挑戰看看自己在短時間內對知識的理解程度。
30天連續發文不只考驗技術
經過評估,我走的是微囤貨路線,因為我是在 9/2 開賽前幾天才知道有鐵人賽這個活動,剛好我的下一個近期目標是對 JS 這個語言更有系統性的認識,當時是覺得這個活動可以用來挑戰一下自己,也正好可以之前寫的 原子化學習 裡面把知識最小化的學習方式做實作驗證,所以想了一下大概要寫什麼之後就跳坑了。到了開賽期限 9/16 前一天,我硬生出大約 10 來篇準備留著緩衝。
沒想到正式開賽才發現我完全低估每天必須發文所帶來的壓力了,因為事先沒有累積太多文章的關係,我幾乎每天都在想著下一篇文章的內容怎麼寫、大綱怎麼擬定、要怎麼畫出核心概念圖才能讓人比較好理解之類的問題。這樣子的狀況持續到大概第 20 篇的時候是最痛苦的,因為越後面的主題我越不熟,需要越多時間,而前面的幾篇卻也因為思考解說方式跟準備圖例的關係花了不少時間,留下來的緩衝時間所剩無幾。
在這個時間點想繼續寫覺得吃力,想放棄又覺得不太對,瞬間覺得自己好像在跑一場已經完成 2/3 ,明明心裡知道快結束了但眼前就是還看不到終點線的尷尬窘境。所以我深深覺得鐵人賽除了考驗技術熟悉度更考驗筆者的心理耐力。在最後雙十連假那幾天實在是最難受的,雖然咬著牙硬寫完了,但是基本上我是ㄧ邊配獵人邊寫完的(喂
使用工具
工欲善其…咳咳,好廢話不多說,稍微介紹一下我這幾天用來幫助寫文章工具,基本上有三個:
-
Notion
在正式開賽之前,我先用 Notion 的 Table 整理了三十天的大綱,雖然最後沒有完全ㄧ樣,不過可以讓自己對文章主題有個底,時間的掌握也比較精準,哪些主題自己比較不熟的話就要預留比較多時間。
-
簡單的流程圖繪製軟體
這種軟體的選擇就比較多,我是選 Sketch,一來之前有學過一點,二來覺得他匯出圖片很方便,雖然他主要是用來前端介面設計的工具,但是拉拉簡單的區塊跟流程箭頭還是很好用的。還有另外一套網頁版繪圖軟體也很推薦:Draw.io
- 瀏覽器開發者工具:
因為我寫的主題不是製作產品型的主題,許多範例程式碼只要可以馬上確認結果就好,這個時候整個瀏覽器都是我的實驗場 :D
是音樂,我加了音樂
如果你以為我是像老派英雄主義電影裡的主角ㄧ單單靠著強大的意志力就輕輕鬆鬆寫完 30 篇文章練成鐵人那就錯了,我也希望我可以。 我曾經抱著很中二的想法,覺得如果世界上沒有音樂的話,我們幹嘛活著?老實說我現在還是深深這麼想的,大概今後也會一直這麼中二下去。總之最後來介紹一下陪伴我度過這地獄般 30 天的幾首曲子:
-
Tauk - Horizon :
風格上屬於前衛搖滾,我很喜歡他們華麗的效果器加上風格多變的主奏電吉他,雖然沒有人聲,但總能聽得我熱血沸騰,附上近期喜歡的一首曲子:

-
Takami Nakamoto - Ashes:
這個音樂家的作品風格定位上還是比較偏電子舞曲,一般人聽來可能會覺得比較實驗性或藝術性,但我真的很喜歡各種奇異材質的聲響。想暫時脫離現實生活看一下不ㄧ樣世界樣貌的絕對推薦(建議戴耳機):

-
Mariya Takeuchi - Plastic Love :
這首毫無疑問是經典,我真的很喜歡遍佈整首的 Disco 元素,前奏剛下沒多久眼前就浮現煙霧彌漫然後雷射燈球光芒四射的場景,查了一下定位屬於 City Pop ,City Pop 是在 1970 日本傳統音樂受到西方音樂文化元素的影響而發展出來的獨特曲風,在當時由山下達郎組成的樂團 SUGAR BABE 帶起風潮。而竹內瑪莉雅就是山下的妻子,也是早期非常有名的音樂家之一,這首歌在前陣子 City PoP 復甦的時候出現在我的推薦歌單內,聽過後立刻愛上。

-
The Brand New Heavies :
這個團體是 Acid Jazz (酸爵士) 的經典團體之一,Acid Jazz 緣起於 Disco 文化,在 1980 年代開始變成風潮,當時舞廳的 DJ 嘗試將爵士樂中的樂句加以取樣,融入電子音樂裡面並融合了靈魂樂、Funk、R&B 等曲風,因而吸引了年輕世代跟老年族群的注意,也是一個讓當代大眾重新開始接觸爵士樂的契機。
雖然在 1987 年由知名唱片經營者 Eddie Piller 與 DJ Gilles Peterson 創立同名自有品牌後才正式被命名,不過 Acid Jazz 這種風格受 60 年代迷幻文化影響至深。( Acid 同時也是迷幻藥的別稱 )所以你常常能在這種曲風裡面聽見運用電子特效達成的迷幻效果,同時又因為強烈的律動感而忍不住開始擺動身體,讓我們來聽聽看 The Brand New Heavies 今年出的專輯同名歌曲,你一定會很喜歡:

總結
原本以為在我整理完過去的學習經驗,寫出原子化學習已經是我自己在今年最有標誌性的里程碑了,沒想到又幹了一件突破自己耐力極限的事情啊 (X。老實說好幾次都以為我沒辦法完賽了,我也不知道是什麼讓我可以支撐到最後,也許是賽期後半段開始陸陸續續有人追蹤,甚至有讀者會參與內容的討論以及告知筆誤,讓我覺得有莫名一股一定要繼續寫下去的責任感。
其實後面還想有寫但來不及寫的主題:演算法跟設計模式,但在我寫這篇文章的當下,已經有些厲害的工程師以演算法當成 30 天的主題並且已經或快要完賽了:
上面稍微推薦一下幾個很棒的相關系列,接下來完賽後我陸陸續續也會去看之前沒時間看的那些主題,如 神Q超人的 TypeScript 或是 六角校長的職場教學,讀者有興趣的話之後也可以跟我一起惡補回來 ( X 。


